

AI vs Human Error: Where Machines Win, Where They Fail, and Why Hybrid Beats Both
See where AI beats human error—and where it fails. Learn why hybrid human+AI workflows cut misses, false alarms, and risk


TL;DR
“Error rate” isn’t one universal number. Depending on the domain, it can mean missed cancers, mistranscribed words, misrouted tickets, false fraud alerts, escaped defects, buggy code, or crashes per mile.
When the task, data, and metric are directly comparable, AI can match or, in some settings, exceed individual human performance on narrow, well-defined perceptual or classification tasks (this is domain- and setup-dependent).
The practical question isn’t “Who wins?” It’s how each fails. AI tends toward systematic failures under data shift or edge cases. Humans tend toward inconsistent misses under fatigue and workload.
The most useful operating model is complementarity: AI reduces high-volume, repetitive error; humans reduce context and judgment error. The best outcomes come from designing human+AI workflows on purpose.
Introduction
Every leadership team is being asked some version of the same question: Is AI more accurate than people? The honest answer is: it depends because “accuracy” changes meaning across domains, and comparisons only hold when the task and evaluation setup align.
This article compares AI vs human error rates and error profiles across nine domains: medical imaging/diagnosis, transcription (ASR), translation (MT), content moderation, fraud detection, manufacturing QA, customer support triage, software bugs, and driving perception. For each domain, you’ll see (1) a short insight paragraph on the typical error profile, followed by (2) brief examples of where AI failed, where humans failed, and where a hybrid workflow helped (when available). Throughout, any statements about “AI vs human” performance should be read as conditional on the specific task, dataset, and metric.
At-a-glance: what each tends to reduce
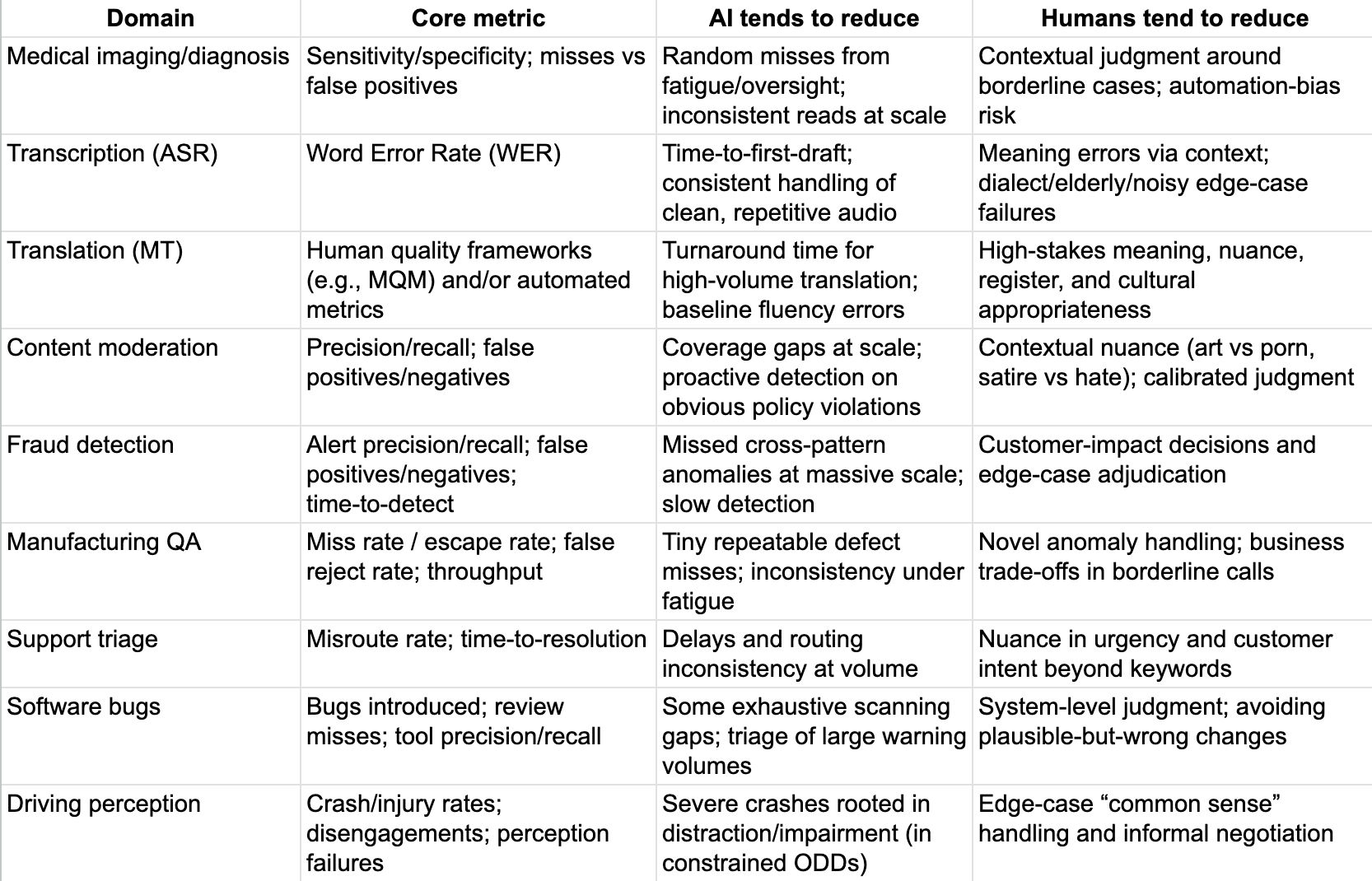
Domain-by-domain: insights and case briefs
1) Medical imaging and diagnosis
AI can be non-inferior to expert double reading in screening-style imaging tasks. In practice, pairing AI with clinicians can reduce missed findings while keeping false positives manageable.
The pattern that matters is error shape. Radiologists may miss subtle lesions due to fatigue or “satisfaction-of-search.” AI may miss cases that fall outside learned patterns or that sit near decision thresholds. Safety depends on how uncertainty is handled, and whether the workflow reliably triggers a second look when something is borderline.
Case Study - AI failed
In a Swedish mammography screening trial, the AI system occasionally assigned low suspicion to a subtle finding that a human reader flagged as concerning. The human’s concern triggered follow-up that identified a cancer the AI would likely have missed under that threshold setting. This is a classic systematic miss: borderline cases can slip through when the system is tuned for higher specificity. A practical mitigation is independent second reading (or structured review of uncertain negatives) so weak signals still get a human “second look.”
Case Study - Human failed
In a pathology example, an AI system highlighted a small focus of intestinal metaplasia that the original pathologist—and multiple independent human reviewers missed on initial review. The finding was confirmed only after the AI prompt triggered re-examination. This maps to a human vulnerability: subtle, low-salience patterns can be overlooked, especially under time pressure. Using AI as a second reader is a direct mitigation for small or rare signals.
Case Study - Hybrid approach
A hybrid failure mode can occur through automation bias: an AI chest X‑ray tool did not flag an early pneumothorax, and a less experienced clinician deferred to the “no acute findings” output despite noticing a faint sign. A senior reviewer later identified the issue. Here, an AI omission became a human miss because the workflow treated AI as authority. Mitigation is UI and training that preserve independent judgment and require escalation when a clinician has uncertainty.
2) Transcription (ASR)
Transcription has clear metrics, especially WER, but performance is highly condition-dependent. On clean audio, modern ASR can approach human-level WER. Under accents, elderly speech, and domain shift, error rates can become extreme far worse than typical human transcription.
Humans often make smaller, more random errors, but can use context to preserve meaning. The most reliable operational pattern is hybrid: ASR drafts, humans correct.
Case Study - AI failed
In a medical dialogue example (older patients, accented speech), ASR error rates were reported in a range where meaning can be distorted illustratively, one model’s WER was ~84% and a commercial system’s was ~59% in that setting. This isn’t a minor degradation; it’s a failure of reliability under real-world speech conditions. The failure mode is systematic mismatch: accents, elderly speech, and clinical vocabulary outside training data. Mitigation is treating ASR as draft-only and requiring human correction in high-stakes contexts.
Case Study - Human failed
A court transcription vignette describes a high-impact human error: “I do have an alibi” was transcribed as “I don’t have an alibi.” The mistake changed meaning and was only corrected after audio re-check. This shows that human transcription can fail catastrophically, not just cosmetically, especially under workload. Mitigation is verification on critical passages and routine audio review for ambiguity.
Case Study - Hybrid approach
In hybrid workflows, ASR produces a first draft and human editors correct it. Reported outcomes include around 5× faster turnaround, with final error rates <1% after human editing. The key point is not “AI is accurate,” but “AI makes the work editable,” letting human attention focus on meaning-critical corrections. Hybrid here is a reliability strategy, not just a productivity hack.
3) Translation (MT)
Translation quality is hard to collapse into a single number. MT systems often reach roughly 70–85% accuracy on straightforward content, versus ~95–100% for professional humans in similar settings. In one evaluated setting, GPT‑4 can be comparable to junior human translators in accuracy, while still lagging senior experts in stylistic finesse.
The error profile difference is predictable and dangerous if ignored. AI can be fluent yet wrong in meaning. Humans can introduce interpretive bias or inconsistency. The safest operating model is machine draft plus human post-editing, with quality gates for high-stakes use.
Case Study - AI failed
In a medical translation near-miss, an AI mistranslated dosage guidance (e.g., “once daily”), creating a potentially dangerous instruction. The error was caught before harm, but it illustrates a critical point: fluency is not safety. The failure mode is semantic precision small wording shifts can carry high consequence. Mitigation is mandatory verification for medical/legal translation and structured review processes.
Case Study - Human failed
Human translators can introduce interpretive shifts, especially in culturally sensitive or nuanced text—because humans optimize for tone and intent, not only literal meaning. In comparative evaluations, this can appear as omissions or meaning drift relative to a stricter reference. This isn’t “humans are worse.” It’s that humans are not neutral instruments. Mitigation is explicit translation standards (what the work is optimizing for) and independent review on sensitive content.
Case Study - Hybrid approach
A post-editing pitfall shows how hybrid workflows can fail if humans relax vigilance when MT output looks polished. A subtle meaning error in an otherwise fluent machine draft slipped through because the human treated the task like proofreading, not verification. This is automation bias in linguistic form. Mitigation is quality gates and reviewer training that assumes “looks good” can still be wrong.
4) Content moderation
Moderation is often “not directly comparable” because ground truth depends on policy and context. Still, the recurring pattern is consistent: AI operates at scale and catches obvious violations, but struggles with nuance. Humans handle nuance better, but show fatigue, inconsistency, and limited recall at volume.
The precision/recall trade-off is the center of gravity. Aggressive automation catches more harmful content but risks wrongful takedowns. Many platforms shift toward targeting clear-cut severe violations while routing edge cases through appeals or specialized review.
Case Study - AI failed
An artistic nude photograph was automatically removed despite policy allowing certain contextual nudity. It was later restored after appeal, illustrating an AI false positive where context matters. The error type is over-blocking with delayed correction. Mitigation is stronger context handling plus efficient escalation and appeals pathways.
Case Study - Human failed
Human inconsistency and inter-annotator disagreement show up on borderline cases: similar content can receive different decisions depending on reviewer judgment and workload. This produces uneven enforcement both missed violations and inconsistent removals. The failure mode is variability under ambiguity at scale. Mitigation includes structured guidance, calibration, and AI assist signals that standardize triage.
Case Study - Hybrid approach
When human review capacity is reduced, automation errors persist longer. During a period when appeals were constrained, far fewer mistaken removals were reversed compared to periods with normal appeals volume. The takeaway is simple: hybrid outcomes depend on the system, not just the model. Mitigation is tiered review so AI handles obvious violations and humans handle the contested, context-heavy cases.
5) Fraud detection
Fraud is a “needle in a haystack” domain: fraud is rare, and the cost of missing it is high. Traditional rule-based systems can generate ~95% false positives, overwhelming investigators and frustrating customers.
ML systems can materially improve precision and detection speed—especially by linking patterns humans miss. The operational frontier is workflow: AI prioritizes and correlates; humans adjudicate edge cases and manage customer impact.
Case Study - AI failed
An ML fraud model flagged many legitimate peer-to-peer payments (including rent), creating customer friction and mistrust. The error type is false positives triggered by pattern similarity (round amounts, “rent” memos) during heightened scam conditions. Mitigation included model tuning and shifting from auto-blocking to tiered verification for medium-risk cases. The lesson is that fraud accuracy and user experience are inseparable.
Case Study - Human failed
A human investigator approved small refund requests that looked plausible individually, missing they were part of a coordinated fraud ring. Humans tend to see queues; fraud often hides in networks. The failure mode is cross-case linkage miss under fragmentation. Mitigation is AI correlation across accounts, devices, and behavior patterns.
Case Study - Hybrid approach
In hybrid setups, AI flags and prioritizes likely fraud, and human analysts make final decisions—reducing alert volume while also reducing missed fraud. In several examples, AI surfaced non-obvious connections that changed the investigation outcome, but humans controlled the action. Hybrid here is both accuracy and harm-reduction: fewer false blocks, faster intervention when risk is real. The system works when thresholds map to downstream actions (block vs review vs notify).
6) Manufacturing QA (visual inspection / defect detection)
Manufacturing QA typically measures error through miss/escape rates and false rejects (scrap/rework), plus throughput impact. Human visual inspection error rates are reported around ~10–20%, driven by fatigue and subjectivity. Modern deep-learning vision systems can claim ~99% defect detection accuracy in controlled contexts.
A critical distinction: legacy rule-based AOI (high false alarms and misses) is not the same as modern AI vision. The best-performing pattern is a team-up model: AI scans 100%, humans verify flags and handle novel anomalies.
Case Study - AI failed
An electronics manufacturer’s older rule-based AOI system flagged ~15% of boards as defective, but only ~5% were truly defective after re-check, meaning ~10% were false positives that created bottlenecks. This is a failure of rigid pattern rules and poor context discrimination (noise vs real defects). Upgrading to a modern AI vision model reduced false rejects dramatically (to ~2%) while improving throughput. The key is not “automation,” but the difference between brittle rules and learned variation tolerance.
Case Study - Human failed
In one case, a small crack defect escaped because a human inspector missed a rare, subtle flaw in a high-volume setting. When AI was trained on images of the cracked parts, it detected the signature reliably, enabling 100% inspection with humans verifying and handling rework. The lesson is classic: rare, small-signal defects are exactly where humans are vulnerable. Mitigation is training AI on that signature and structuring verification rather than relying on vigilance.
Case Study - Hybrid approach
A composite materials plant implemented AI scanning for tiny weave defects but initially faced too many false defect flags when running AI alone. Switching to a hybrid approach - AI marking potential defects and a human confirming/overriding, achieved near-zero misses with minimal false rejects. AI finds everything; humans filter noise and keep operations practical. Hybrid works when humans retain ownership of the final call and feedback loops improve the model.
7) Customer support triage (routing / classification / priority)
Support triage errors show up as misroutes, misprioritization, and delays. Automated classifiers can materially improve routing accuracy and reduce misroutes, while also reducing assignment time from manual handling to near-instant tagging.
Humans add nuance—intent, urgency, and customer context—but under surges they become bottlenecks. A robust pattern is AI suggesting categories/priorities (ideally with confidence), and humans overriding on ambiguity.
Case Study - AI failed
A telecom deployed an AI ticket classifier that initially misrouted many outage reports as billing issues because the model overweighted keywords like “credit” and “refund.” In one outage incident, 50+ customers waited hours because tickets sat with the wrong team. The failure mode is brittle text classification without situational context and without a feedback loop. Mitigation included retraining on outage examples and adding a rule to auto-tag spikes of similar tickets as potential outages, plus a clear path for manual rerouting.
Case Study - Human failed
In one bank, manual triage created average delays of several hours before emails were categorized and forwarded. During surges, urgent fraud reports sat in general queues too long an error of omission/delay rather than incorrect labeling. The failure mode is 24/7 scale limits and inconsistent prioritization under workload. Mitigation was implementing real-time AI tagging so urgent cases are escalated within minutes.
Case Study - Hybrid approach
In hybrid support setups, an AI assistant handles common, repetitive queries and collects the right details up front, then escalates exceptions to a human agent. The AI’s role is to reduce delay and standardize intake; the human’s role is to apply judgment on edge cases, goodwill decisions, and emotionally sensitive situations. The benefit is not only faster response, but better allocation of human attention to the cases where it changes the outcome. Hybrid delivers speed and judgment when escalation rules are clear.
8) Software bugs (detection, review misses, assistance impacts)
Software has multiple “error surfaces”: bugs introduced, bugs missed in review, and false positives that prompt unnecessary changes. A key pattern is the precision/recall trade-off: static tools can have higher recall but lower precision (creating warning fatigue), while humans catch fewer issues but are more precise when they do.
There is evidence that AI coding assistance can increase bugs and vulnerabilities when used without guardrails speed rises, scrutiny falls. The practical takeaway is that software quality is a socio-technical problem: tools shift error distribution unless the workflow compensates.
Case Study - AI failed
In AI-assisted code generation and security tasks, AI suggestions produced insecure or buggy code at a meaningfully higher rate than baseline human work in that setting. The risk is “plausible code”: it compiles, looks standard, and still carries subtle vulnerabilities. The failure mode is learned repetition of seen-before patterns, including insecure idioms. Mitigation is strict human review, targeted security training data for models, and stronger automated testing.
Case Study - Human failed
Human code review inevitably misses defects, with illustrative ranges where review might catch only a fraction of bugs depending on time and expertise. This becomes especially risky under deadline pressure: missing a safety check or edge-case path can slip into production. The failure mode is bounded attention humans don’t exhaustively scan everything. Mitigation is process (release discipline, checklists) and tool support that surfaces high-risk areas.
Case Study - Hybrid approach
An emerging hybrid direction is straightforward: AI helps filter and prioritize static analysis warnings and can generate targeted tests, while humans apply judgment to a reduced, higher-signal set. The goal is to combine AI thoroughness with human context, improving signal-to-noise and reducing warning fatigue. Hybrid succeeds when “AI output” triggers more verification, not less. Without that shift, automation bias can turn tool errors into shipped defects.
9) Driving perception (ADAS/AV perception + safety proxy metrics)
Driving “error rate” is not a single perception metric. It is safety outcomes (crashes, injuries) and proxies (disengagements, interventions) within specific operating domains. Within constrained operational design domains (ODDs), some autonomous fleets report lower injury crash rates than general human driving averages in comparable areas - an important claim that remains contingent on operating domain and measurement method.
At the same time, AVs can fail in edge cases that humans handle routinely. And “safe fallback” behavior can still be a mission failure even if it avoids a crash. Comparability depends on ODD: environment matters as much as model capability.
Case Study - AI failed
“Phantom braking” describes a perception/decision failure where a system brakes hard despite no hazard, creating risk for following traffic. This is not a minor classification error; it’s an action-level failure with safety implications. The failure mode is conservative logic triggered by misperception or uncertainty. Mitigation includes model/sensor improvements and safer takeover pathways.
Case Study - Human failed
A core human driving error profile is that distraction, impairment, and aggression drive many high-severity crashes that automated systems, by design, avoid. Human drivers don’t “fail safe.” They improvise through confusion, sometimes successfully, sometimes with catastrophic results. The “error rate” in driving is ultimately measured in crashes and injuries, and humans produce a steady background rate of severe failures. Mitigation is assistance systems that reduce common human failure roots, while keeping the driver attentive where responsibility remains.
Case Study - Hybrid approach
A widely cited 2018 fatal crash case illustrates a combined failure: the automated system misclassified a pedestrian at night and did not brake in time, while the safety driver was distracted and did not intervene. This is a hybrid breakdown - AI perception failure plus human monitoring failure amplified by over-trust and weak engagement design. The mitigation theme is explicit: stronger driver monitoring, clearer responsibility boundaries, and interfaces that prevent complacency in partial-automation regimes.
Patterns and themes across domains
Error trade-offs (precision vs recall) are universal
Systems are rarely “just accurate.” They are tuned. Higher recall catches more true issues but increases false alarms; higher precision reduces false alarms but risks misses. Screening, moderation, and fraud make this visible: different stakeholders choose different equilibria depending on harm. Hybrid workflows can combine strengths AI casts a wide net, humans confirm—but only if review capacity and escalation design are real.
Humans excel at context, AI at scale
Humans interpret intent, nuance, and atypical situations. AI excels at high-volume, consistent scanning: every image, every ticket, every transaction, every frame. The risk is treating scale as understanding. The opportunity is using scale to feed human context rather than replacing it. Across domains, “AI as triage and second reader” is the pattern that best aligns with those strengths.
Human inconsistency vs AI consistency
Humans drift with fatigue, workload, and individual interpretation. AI delivers repeatable thresholds. That consistency is a capability, but it can be dangerous when the system is consistently wrong in a systematic blind spot. The practical implication is monitoring for systematic errors and maintaining feedback loops that let humans correct the model over time.
Over-reliance and automation bias
A recurring failure shows up in imaging, post-editing, and partial automation: humans lower vigilance when AI output looks confident or polished. Automation bias turns AI omissions into human misses. Mitigation is workflow design: show uncertainty, require confirmation on critical items, and train teams to treat AI as input—not authority.
Data shifts and adversarial behavior
AI error rates degrade when inputs shift: new dialects, new fraud tactics, new product designs, novel road situations. Humans are generally more adaptable to novelty, while AI often needs retraining or robust design to handle distribution shift. In adversarial settings like fraud and moderation, attackers adapt to what models detect. Hybrid systems can be more resilient because humans can recognize “this feels off” even when it doesn’t match known patterns.
Error impact and mitigation matter as much as the rate
A 1% error can be trivial in one domain and catastrophic in another. False positives in fraud harm trust. False negatives in medicine risk lives. False positives in moderation silence creators. False negatives in driving can be fatal. Designing the mitigation layer, escalation, verification, uncertainty thresholds, safe fallbacks is often the real differentiator.
“Not directly comparable” scenarios
“AI vs human” comparisons only hold cleanly when tasks, metrics, and ground truth align. Many settings don’t, either because ground truth is partly normative (moderation) or because operating conditions vary dramatically (audio quality, driving environments). In those cases, raw error-rate comparisons mislead. Error profiles - what each tends to miss, what each tends to overcall, and how those patterns shift under stress—are the more actionable lens.
Final words
AI can reduce certain types of human error, especially random and large-scale errors, while introducing new error modes (systematic misses, edge-case brittleness, and automation-driven human lapses). Where tasks, data, and metrics are directly comparable, there are cases where AI can match—or, in some settings, exceed—individual humans on narrow perceptual and classification tasks. Those results should be interpreted within the bounds of the evaluation setup and not generalized beyond it without caution.
The decisive factor is system design. Translating benchmark improvements into real-world outcomes requires thresholds, monitoring, escalation paths, and training that anticipates failure—not just success. The best results come from harnessing complementarity: let AI do what it’s good at (high-volume, high-consistency detection and triage) and let humans do what they’re good at (judgment, verification, handling novelty, and values-based trade-offs). The future isn’t “AI replaces people.” It’s organizations building better socio-technical systems—where humans stay meaningfully in the loop, and the combined system is designed to be safer, more resilient, and more accountable than either could be alone.